Metropolis filter proposal
In this article we will discuss the Metropolis Filter proposal. This proposal is useful, when our likelihood is made up of individual parts, which have different computational cost to be evaluated. It allows us to reject unlikely samples early, i.e. without having to compute all the parts of the likelihood. A typical scenario where this proposal is useful is, when we integrate in a fitting algorithm landmark annotations (cheap to evaluate), contour points (relatively cheap to evaluate) and an ASM likelihood (expensive to evaluate).
Mathematical idea
Let's assume that we have a likelihood that consists of the following independent factors
where are pieces of information that we observe.
The posterior can be computed sequentially by starting from the prior and taking in new information from the likelihood one by one, leading to the chain:
or written explicitly as
where are the usual normalization factors.
This sequence of updates can be implemented efficiently using the Metropolis-Hastings algorithm. We start sampling from the prior distribution. The resulting sample is filtered by the likelihood , which is then subsequently filtered by the likelihood . Filtered here means that the sample from the prior distribution becomes subject to another acceptance rejected step, where the acceptance step is computed using the corresponding likelihood. The idea is illustrated in Figure 1
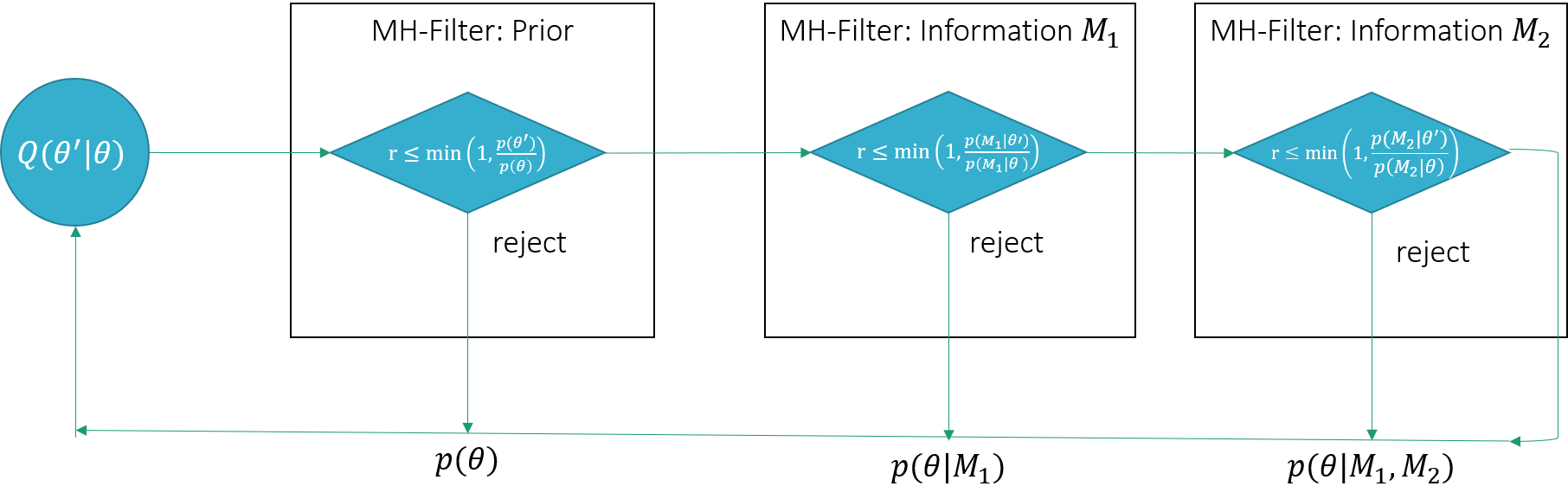
It can be shown that this procedure converges to the desired posterior distribution (see e.g. Schönborn, Section 5.3.41). The advantage of this implementation is clear: We do not have to compute the likelihoods in the later stages when a sample is already rejected in the first step of the filtering algorithm.
Implementation in Scalismo
The practical implementation of this filtering step is straight-forward. We simply create a special proposal, which internally runs one step of the Metropolis-Algorithm. In Scalismo, this is already implemented. It can be used as follows
val priorEvaluator : DistributionEvaluator[Sample] = ???
val proposalGen : ProposalGenerator[Sample] = ???
val metropolisFilterProposalGen1 = MetropolisFilterProposal(proposalGen, priorEvaluator)
val likelihoodEvaluator1 : DistributionEvaluator[Sample] = ???
val metropolisFilterProposalGen2 = MetropolisFilterProposal(metropolisFilterProposalGen1, likelihoodEvaluator1)
val likelihoodEvaluator1 : DistributionEvaluator[Sample] = ???
val mh = MetropolisHastings(metropolisFilterProposalGen2 , likelihoodEvaluator2)
References
- 1 Schönborn, Sandro. Markov chain Monte Carlo for integrated face image analysis. Diss. University_of_Basel, 2014.